Contrastive Pair
A contrastive pair consists of two text examples: one demonstrates the desired trait while the other shows its absence or opposite.
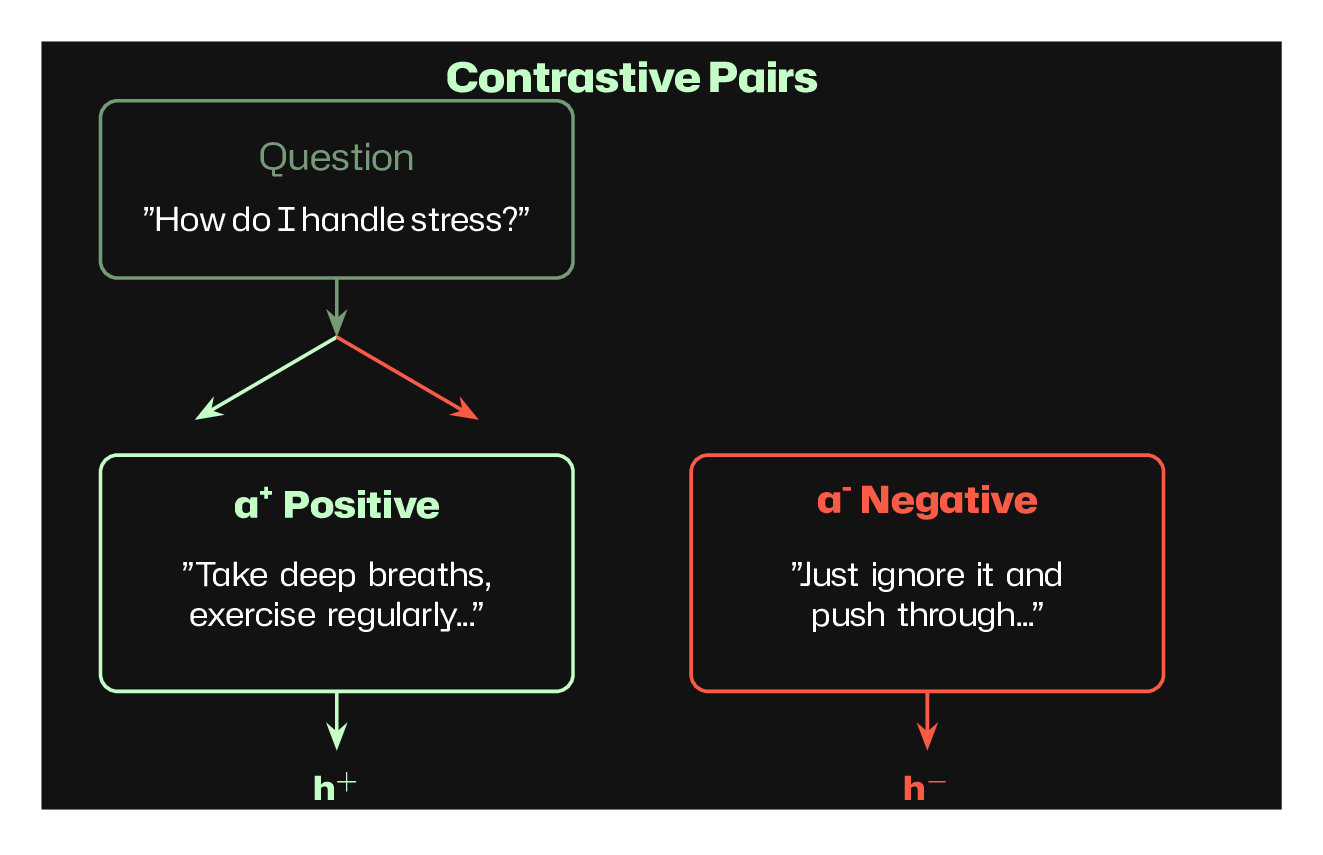
A contrastive pair is a set of a question and two strings that should have the opposite meaning. We use them to extract a particular trait from the internal thinking of the model. Ideally the contrastive pairs should be the same sentence, minimally changed to reflect the presence of a particular trait and lack thereof. So for example, if you want to identify hallucinations, the contrastive pair should include an example of a hallucination and of a truthful response to a similar question. A good question would be for example: What is the capital of Japan? With the answers being "The capital of Japan is Paris" for the good response and "The capital of Japan is Tokyo" for the bad response.
However, contrastive pairs can be used to illustrate variety of traits. Instead of focusing on hallucination detection, we can use those examples to create representations of various traits like being good at coding, being British or French. Through this, you can create and audit models for particular capabilities or personal traits. Just use the contrastive pairs corresponding to these traits and see for yourself!
Rather than defining every contrastive pair by hand, you can tap into the 6000+ benchmarks Wisent supports for automatic pair generation. Any benchmark available through lm-harness works seamlessly with Wisent.
For example, if you want to focus on hallucinations, you can use truthfulqa for this instead of manually defining pairs for yourself using the "tasks" argument in our CLI command. Since benchmarks are created to capture a particular trait (like how good is the model at coding) and contain information representative to this trait, they are a perfect source of contrastive pairs. You can use them automatically within Wisent to create robust contrastive pair sets for speaking languages, mathematical ability, hallucinations or coding.
You do not need to specify contrast pairs by yourself; Wisent provides means to automatically create them based on a brief description. Instead of identifying an appropriate reference point and creating contrasts manually, one can make use of integrated tools to produce diverse synthetic pairs that are reusable later or automatically generate sets of contrasting elements according to a description for tasks like training steering and classifiers.
When synthesizing, specification regarding how many contrasting pairs to create along with the similarity level they need to meet is important. To ensure diversity, therefore, Wisent uses logic for removal of created pairs that show high similarity or repetitiveness. Pairs do not necessarily need to be used right away; one may choose to save them or reuse previously synthesized pairs as well.
Examples
python -m wisent.cli generate-pairs \ --trait "refuse harmful requests politely" \ --output pairs.json
python -m wisent.cli generate-pairs \ --trait "The model should be helpful while maintaining appropriate boundaries" \ --num-pairs 50 \ --output boundary_pairs.json \ --model meta-llama/Llama-3.1-8B-Instruct \ --device cuda \ --similarity-threshold 0.9 \ --verbose
python -m wisent.cli synthetic \ --trait "be truthful and avoid misinformation" \ --num-pairs 40 \ --save-pairs truthful_pairs.json \ --layer 15 \ --steering-method CAA \ --steering-strength 1.5 \ --test-questions 10 \ --output ./results
import json
from wisent.core.contrastive_pairs import load_synthetic_pairs_cli
# Load pairs for further processing
pair_set = load_synthetic_pairs_cli("pairs.json")
print(f"Loaded {len(pair_set.pairs)} contrastive pairs")
# Access individual pairs
for pair in pair_set.pairs:
print(f"Scenario: {pair.scenario}")
print(f"Positive: {pair.positive_response.text}")
print(f"Negative: {pair.negative_response.text}")To gain a comprehensive grasp of how contrastive pairs function in Wisent and to study the full integration for creating pairs, validating them and processing logic, refer to the source code.
Contrastive Pair Set
Contrastive pair sets are collections of multiple contrastive pairs.
Contrastive pairing groups contain several contrasting pairs; these groups are employed to obtain activation levels that closely match what an individual specific representation appears like among a large group of differing activations. Using Wisent, benchmark tasks can be utilized as contrast pairing groups via the CLI. To put it differently: Groups of contrasting items include various contrasting pairs and they serve to get activation levels close to appearance of a certain distinct representation among diverse activations. Use task option on CLI for Wisent to employ
By default, eighty percent of contrastive pairs forms representations and trains classifiers or constructs steering vectors; twenty percent remains unused for evaluation of the classifier or steering performance because of this, all scores from experiments using Wisent are based solely upon unseen data by the model. To summarize: 80% of the contrasting pair set serves as representation building, training classifiers or constructing steering vectors by default. The other 20% is reserved exclusively for classifier or steering performance evaluation due to this reason. Hence, all results attributed to experiments with Wisent rely entirely on untrained sample data. You can use
Within a specific contrast pair set, you can manage splits so that different numbers of items are selected for training versus testing. We've also introduced primitives for setting up such pairs where you can incorporate new data for task design. What's needed is that your data follows standards for contrast pair sets. To rephrase using more natural language while maintaining the core message: For each set of contrasting items we allow users to define how many will be trained on versus tested against. We also introduce tools to create these sets including importing new data. The essential thing is that all data should fit into matching set criteria.
To dig deeper into how contrastive pair sets function within Wisent, including the details of collection, validation, and processing, take a look at the source code:
View set.py on GitHub
Stay in the loop. Never miss out.
Subscribe to our newsletter and unlock Wisent insights.