Activations
Activations are all intermediate values computed during a forward pass. Contains the residual stream, but also all the other information like layer norm results, MLP outputs and the like.
When you enter text such as "The cat sat," the model translates this into tokens and then transforms those tokens into number vectors; this transformation happens via embedding mappings. Embedding maps map every token into a specific set of fixed numeric vectors; "cat" will consistently receive the same vector irrespective of context. Every Transformer layer subsequently manipulates these vectors and generates fresh vectors known as activations which reflect the understanding of the model concerning the text up until that particular layer. For instance, with a phrase such as "Wisent is the best startup currently available," standard tokenization splits it into nine tokens ("Wis", "ent", "is", "the", "best", "start", "up", "out", "there"), thus resulting in a total of around 1.2 million different activation values when using Llama 3.1 8 B because of nine tokens multiplied by thirty-two layers and forty-nine hundred dimensions. Thus, activations essentially function similarly to embeddings but they vary dynamically according to the overall context within an entire sentence.
Activations represent the internal state when a model works on generating a particular token. Tokens are word fragments like "Hello" or "world". More precisely, activations are the numerical values at each layer that emerge as the model attempts to produce a given token.
When generating phrases such as "I am a large language model" from an output model, various activations can be extracted to serve in representation engineering; how many specifically depends on the multiplication of token count times layer count. Each of these is a set of numbers. For Llama 3.1 Instruct at 8 billion parameters, this results in vectors with length 1 x 4096.
Wisent aims to capture everything which allows us to conduct detailed analysis and manipulate activation processes during steering but it involves very high computational cost; instead, we utilize just a subset of activation for specific tokens. To be clear, Wisent intends to collect all necessary data to perform comprehensive analysis and modify activation processes through steering; however, processing such large amounts of data incurs an extremely heavy computational burden; therefore, instead of utilizing all collected data, we focus on employing a smaller subset of activations corresponding to certain tokens.
To do this, we define a specific activation collection method. This allows us to create multiple ways through which we are able to collect activations corresponding to different representations. Ideally, we want two vectors that represent behavior corresponding to a representation we want to identify and the opposite of it. So two sets of numbers.
We extract activations from a contrastive pair set. A contrastive pair consists of a question, good response and bad response. We can use different logic to transform this set of strings into activations we will use to create representations from. Wisent allows you to specify what collection method to use using the Activation Collection Method primitive.
Activation Separability
When we collect activations from positive (a⁺) and negative (a⁻) examples of a trait, the resulting distributions can have different separability properties. The figures below show activations projected onto two dimensions (d₁, d₂) of the activation space.
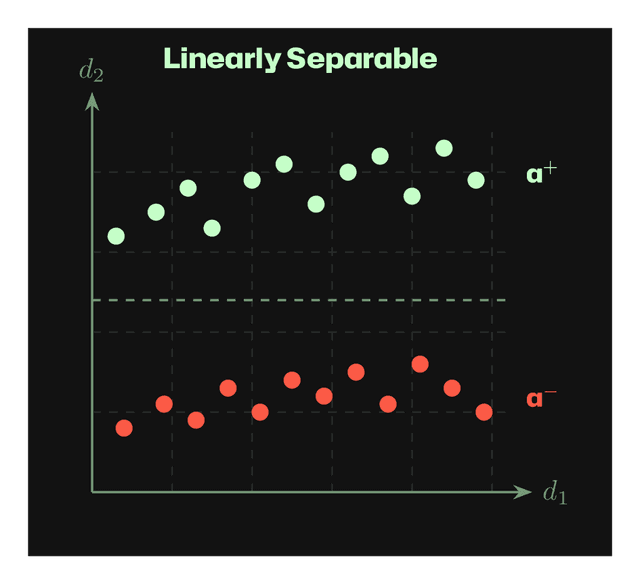
Linearly Separable: A simple hyperplane can separate positive and negative activations. Linear methods like CAA work well.
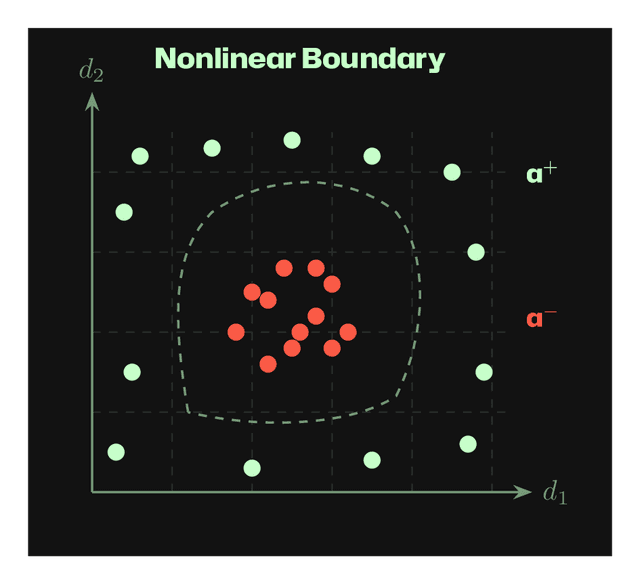
Nonlinear Boundary: Classes are separable but require a nonlinear decision boundary. Methods like MLP probes may be needed.
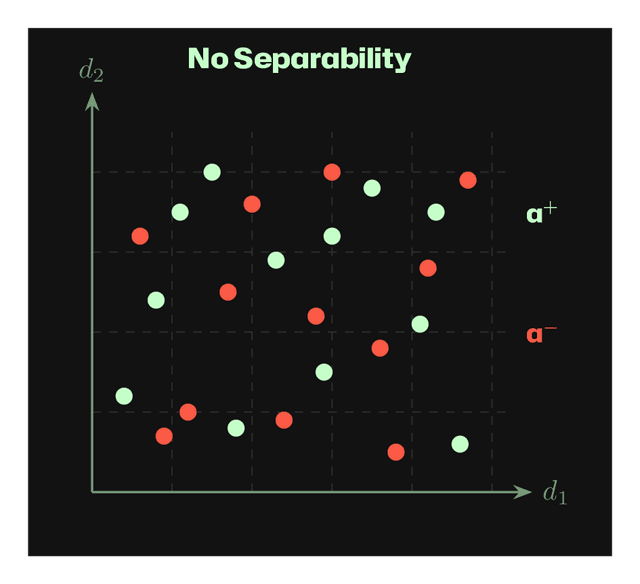
No Separability: The trait is not represented in these activation dimensions. Different layers or collection methods may be needed.
To fully grasp how activations operate within Wisent, along with detailed implementations for aggregation methods, similarity computations, monitoring logic and collection of contrasting pairs, refer to the source code. To fully understand activations within Wisent including detailed implementation of aggregation procedures, similarity calculation processing,
View activations.py on GitHub
Activation Collection Method
The Activation Collection Process gathers information about activation for both contrasting pairings simultaneously to discern features.
Each contrastive pair consists of a question, good response and bad response. Activation collection method shows how for a given model and layer we extract a vector of positive and negative behaviour from those sets. Prompt construction strategies specify how we turn this set into a prompt reflecting the thinking of the model. Token targeting strategies control which token we are extracting the activations from. We have constructed a variety of methods for these purposes that are available as presets for you to use. You are welcome to design more prompt construction strategies and token targeting strategies.
When using defaults (prompt selection strategy plus target choice token strategy), the system retrieves activation values from tokens marked as 'A' or 'B'. For example for prompts such as "What's greater: 2+2? A: 5 B: 4," the system generates two separate variations: one that ends with 'B' and extracts activity data from 'B', another which ends with 'A' and extracts information from 'A'. System scans backward from the end of sequences looking specifically for those distinct tokens and if they cannot be located, fallback uses final token present.
Prompt Construction Strategies
"Which is better: {question} A. {bad_response} B. {good_response}"
python -m wisent.cli tasks mmlu --model meta-llama/Llama-3.1-8B-Instruct --layer 15 --limit 1 --prompt-construction-strategy multiple_choice --verbose
Which is better: Find the degree for the given field extension Q(sqrt(2), sqrt(3), sqrt(18)) over Q. A. 0 B. 4 C. 2 D. 6 Answer: A. This is incorrect B. 1
Token Targeting Strategies
Targets specific choice tokens like "A" or "B"
python -m wisent.cli tasks mmlu --model meta-llama/Llama-3.1-8B-Instruct --layer 15 --limit 1 --token-targeting-strategy choice_token --verbose
Activation Extraction: Searches backwards for "B" token (correct choice), extracts activations from that token position.
Usage Examples
# Multiple choice with choice token targeting (default) python -m wisent.cli tasks mmlu \ --model meta-llama/Llama-3.1-8B-Instruct \ --layer 15 --limit 10
# Role-playing with continuation token targeting python -m wisent.cli tasks truthfulqa \ --model meta-llama/Llama-3.1-8B-Instruct \ --layer -1 --limit 10 \ --prompt-construction-strategy role_playing \ --token-targeting-strategy continuation_token
# Direct completion with last token targeting python -m wisent.cli tasks mmlu \ --model meta-llama/Llama-3.1-8B-Instruct \ --layer 15 --limit 10 \ --prompt-construction-strategy direct_completion \ --token-targeting-strategy last_token
To gain full understanding of how collection methods operate within Wisent involving detailed exploration of strategy implementations, statistical approaches, and optimization techniques, study the source code. Rephrased Version: To fully understand operation of data collection methods in Wisent, as well as investigation into their comprehensive
View activations_collector.py on GitHub
Stay in the loop. Never miss out.
Subscribe to our newsletter and unlock Wisent insights.